LLM inference engines and servers
Updated April 21st 2025
A year ago I wrote an article where I presented the different ways one could deploy an open source LLM. This is a particularly interesting topic to me, so I kept digging.
A lot has changed in just two years within the open source landscape of generative AI. I first started working with open source LLMs in the spring of 2023. Privacy and ownership were my main motivations, but at the time, the options were limited—you could basically choose between LLaMA… and LLaMA.
Jokes aside, there were a few others. I experimented with T5 (Google), Dolly (Databricks), Red Pajama (Stanford), etc. However, GPT4 had just been released, and open source alternatives were not even on par with GPT 3.5, let alone its successor. Not to diminish the great work behind these models. LLMs were a new thing, GPT 3.5 was barely six months old, and as we later saw, it was only a matter of time before open-source caught up.
By April 2023, we had built a LangChain application for our use case. Since we were working on AWS, we deployed the models on SageMaker endpoints. And then another issue emerged…
It was slow – painfully slow. Even with relatively small models. Not suitable for a customer-facing solution. We used the PyTorch Hugging Face deep learning inference container on SageMaker and obviously it was not suited for this job. We were far from the speed of ChatGPT and its token streaming capabilities.
Fortunately, Hugging Face released their TGI powered inference container on SageMaker a month later, which gave our application a significant speed boost! I realized deploying a LLM is one thing, making it fast and efficient is a whole different challenge.
It sparked my interest in LLM efficiency and in understanding inference frameworks and their optimizations.
LLM inference frameworks
You may find different namings on the internet. When I am talking about an inference framework or service, I refer to an end-to-end software that enables to send text inputs to a LLM and get text outputs.
The most popular frameworks mostly remain the same as when I wrote my previous article.
For local inference (on-device execution with CPU and GPU support):
For cloud-based inference (suited for scalable deployment, optimized for GPU):
- vLLM
- TGI
- TensorRT-LLM (+Triton)
There are other alternatives. However these are the most popular ones in the open-source community.
vLLM has become my go-to solution to run a LLM on GPU. It is both very simple to install and to use. It serves a model from a simple command line, outputs comprehensive logs, and makes token streaming easy. It also supports an OpenAI-compatible API, making integration straightforward.
So I have used vLLM since 2023, without much consideration for what was really running behind the scene. Until recently when I stumbled upon something:
Wait, why does Triton Inference Server support a vLLM backend? Doesn’t vLLM already serve models? What’s the point of Triton here?
To me, this did not make sense. That’s when I realized that hidden behind the simple vllm serve command were two key concepts I had not really considered: LLM Inference Engine and LLM Inference Server.
LLM Inference Engines
I have to admit, this concept was a bit foreign to me.
I thought you would use a framework such as PyTorch or TensorFlow to load a model’s weights and architecture and then perform the matrices multiplications. Like a boosted numpy on GPU, right? Well, not quite.
This is close to what we did back in early 2023 with our slow PyTorch container on SageMaker, and as I said, it did not work very well.
PyTorch and TensorFlow are indeed able to load the weights of a model, its architecture and then perform matrix multiplication during a forward pass to provide an output. However, they are general-purpose tensor computing frameworks and are not optimized for LLMs.
What makes LLM so special?
Large Language Models rely heavily on the Transformers architecture. Transformers are based on the attention mechanism which is a scaled dot-product between 3 matrices, $Q$, $K$, and $V$.
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V\]Breathe in, this is the only equation in the article
Each row of these matrices corresponds to one token (a token is a word part that LLMs are trained on).
 Figure 1. Example of tokens seen by ChatGPT
Figure 1. Example of tokens seen by ChatGPT
At inference, tokens are generated one by one which requires a lot of dot-products between these matrices. In pure PyTorch, these matrices are re-computed from scratch at each decoding step, even for tokens that were already seen. So, everytime a new token is generated, everything is forgotten, and the sequence with the new token is fed back. This is why it is slow, and gets slower with longer sequences.
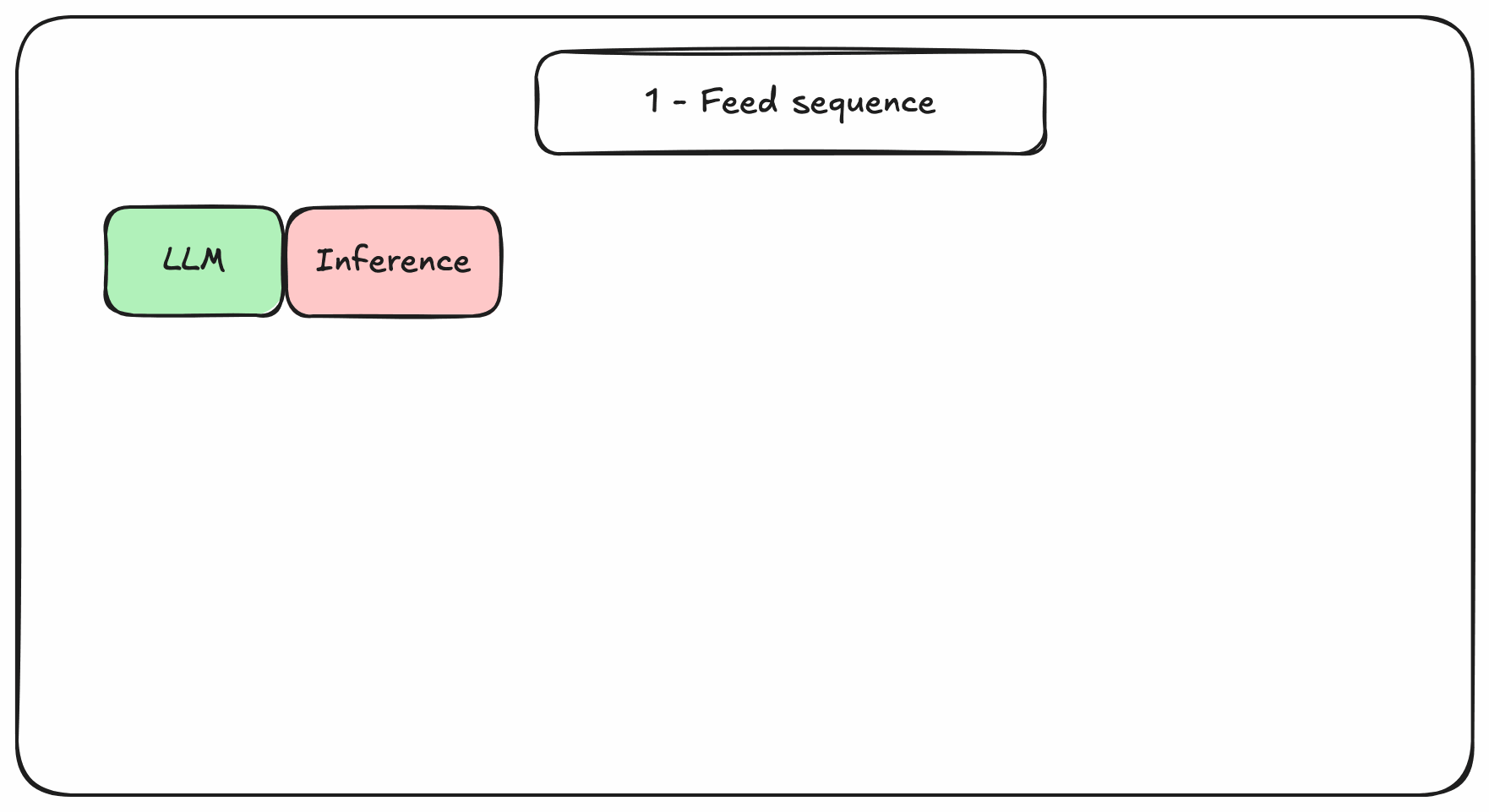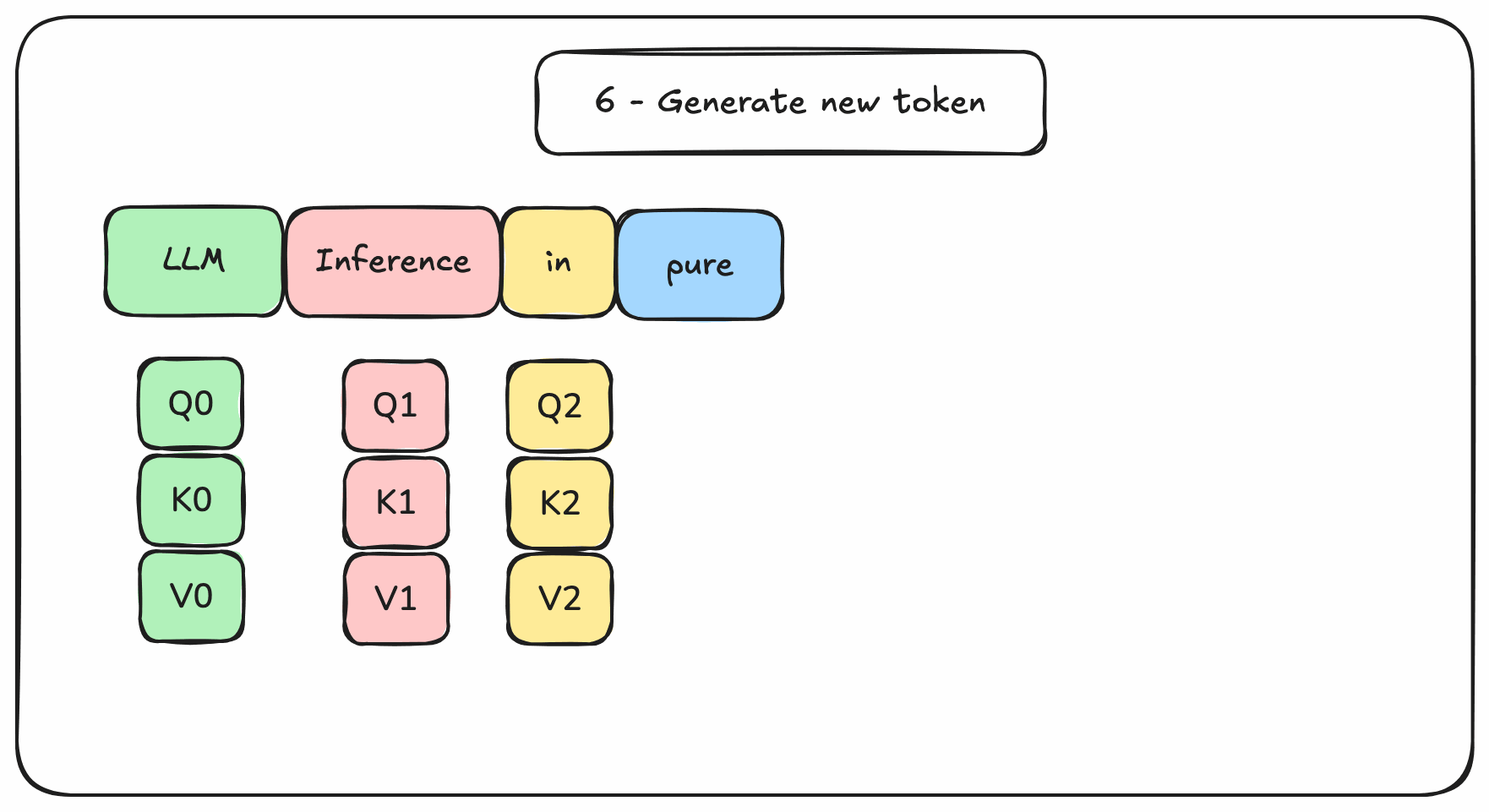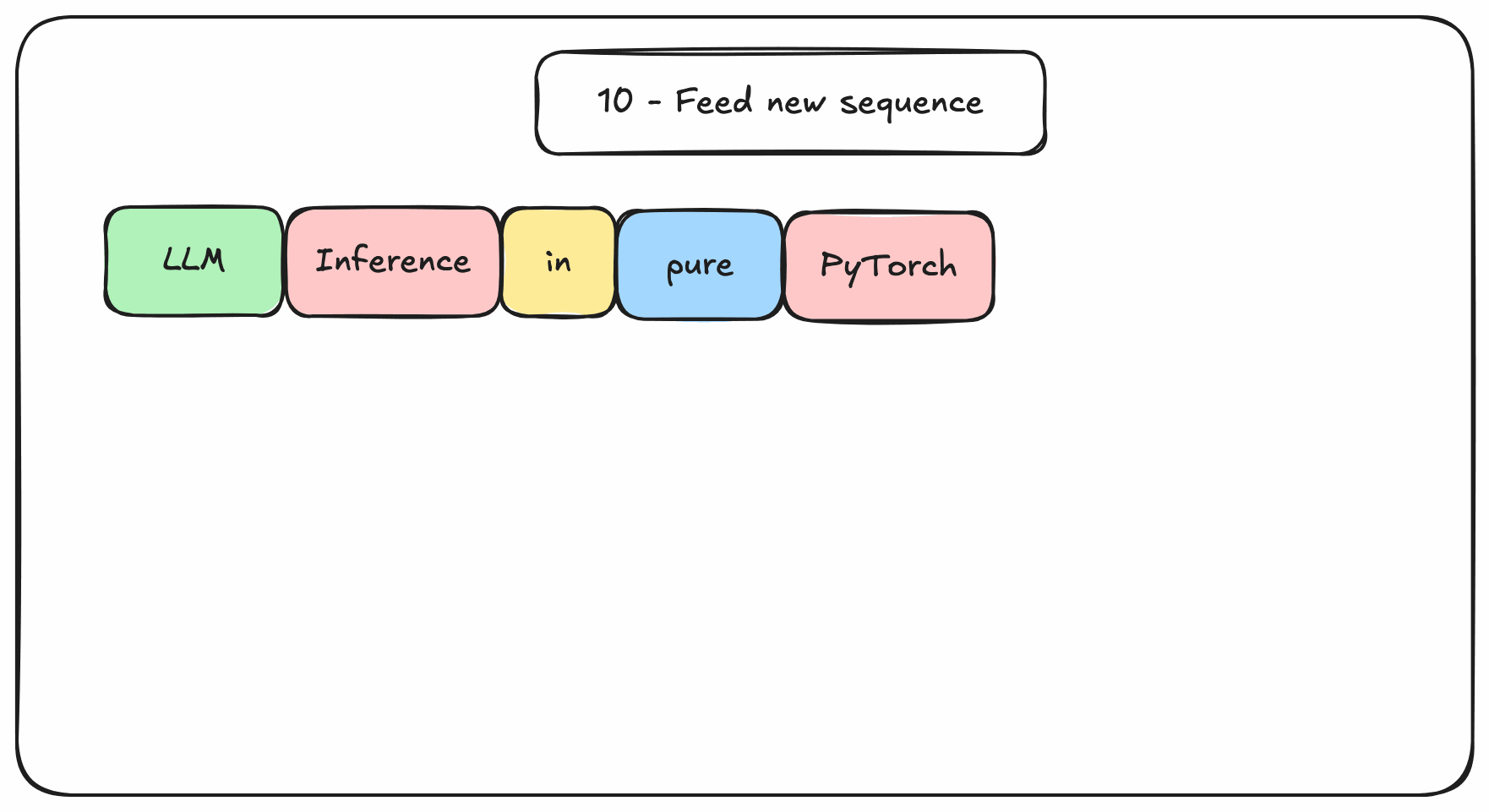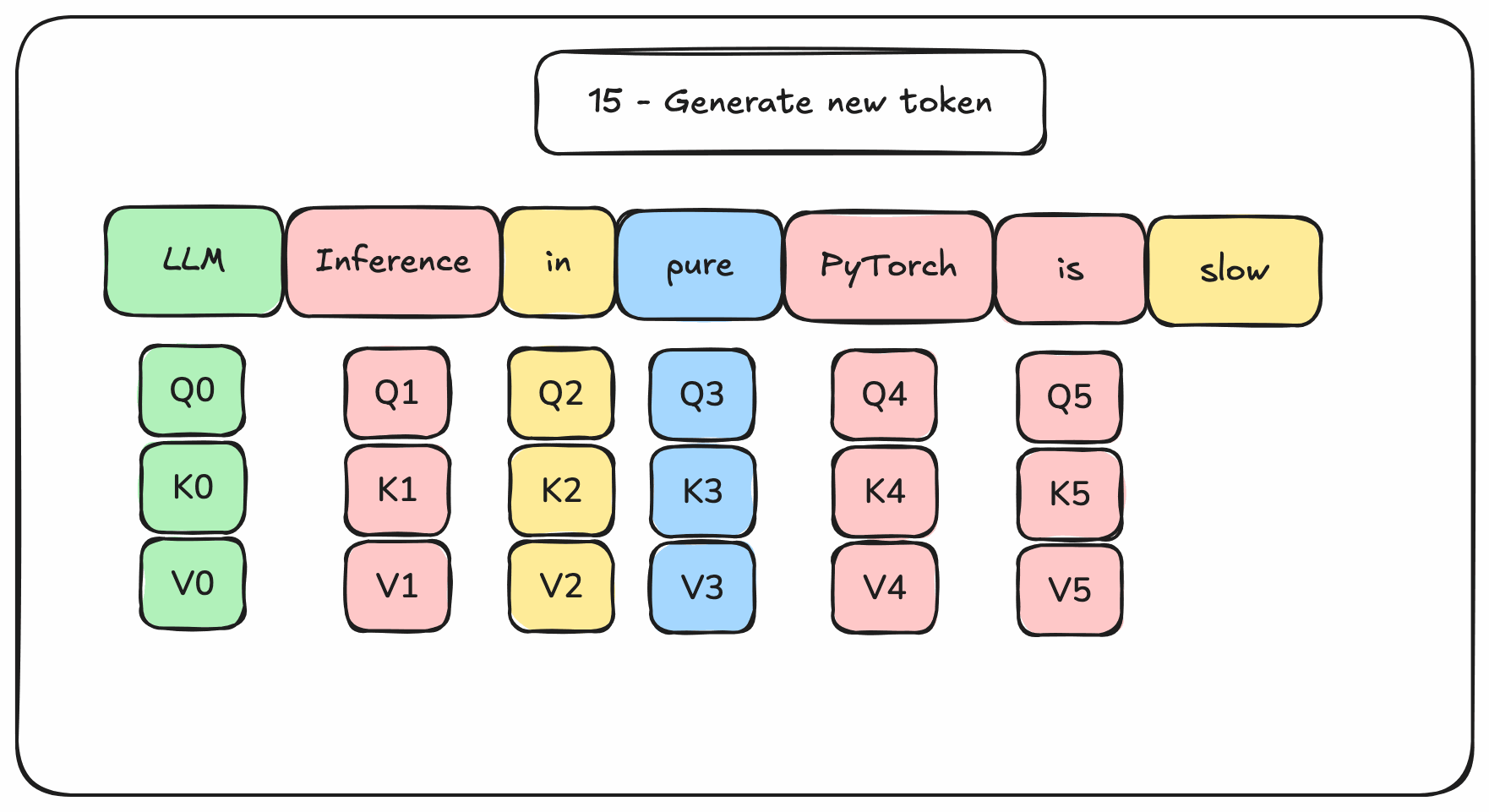 Figure 2. Transformers-based decoding in pure PyTorch
Figure 2. Transformers-based decoding in pure PyTorch
Instead of re-computing all these matrices from scratch, it is better to cache the rows of past tokens in memory. Ideally GPU memory for fast reads. This would avoid wasting GPU resources on redundant computations.
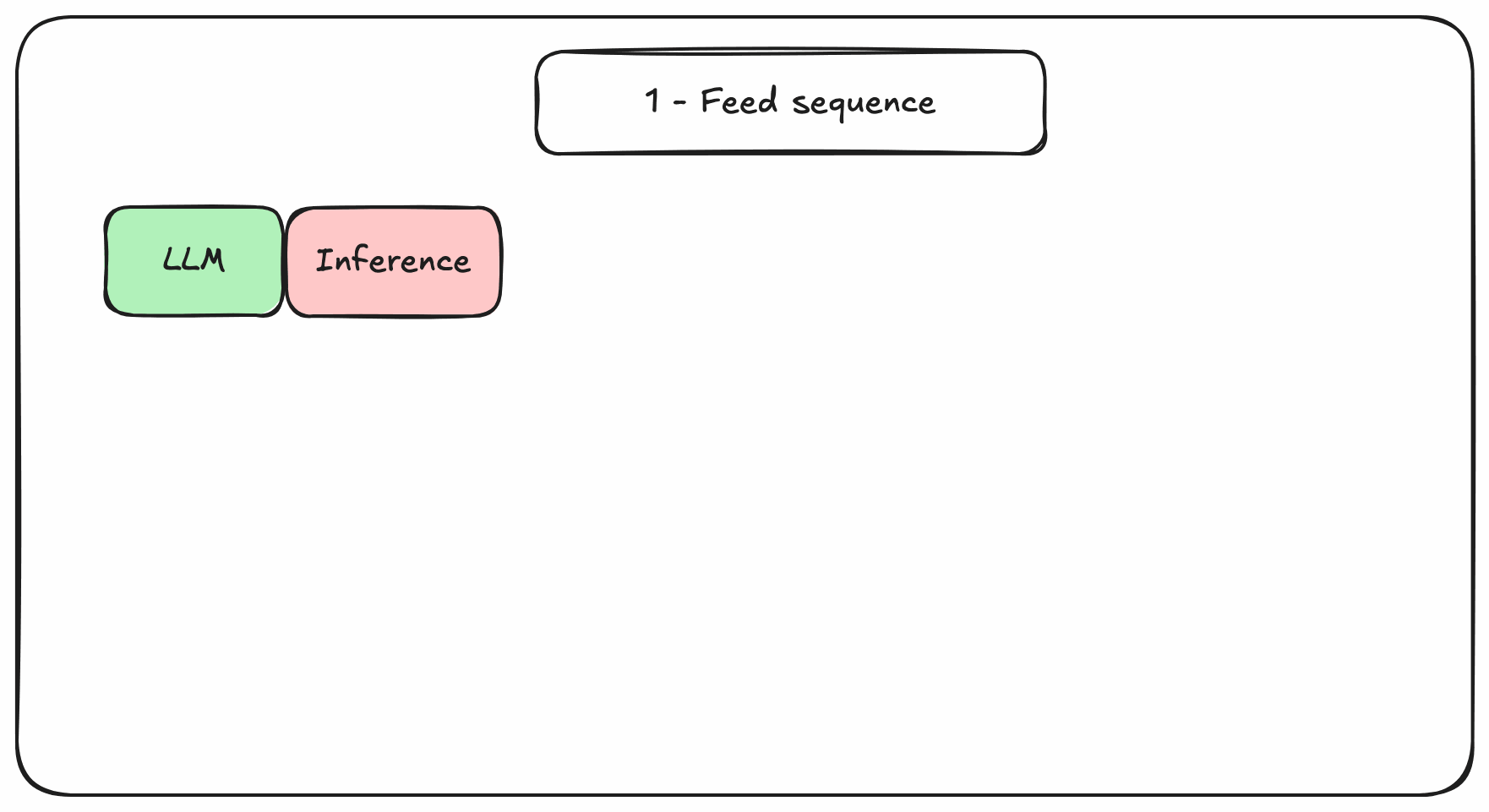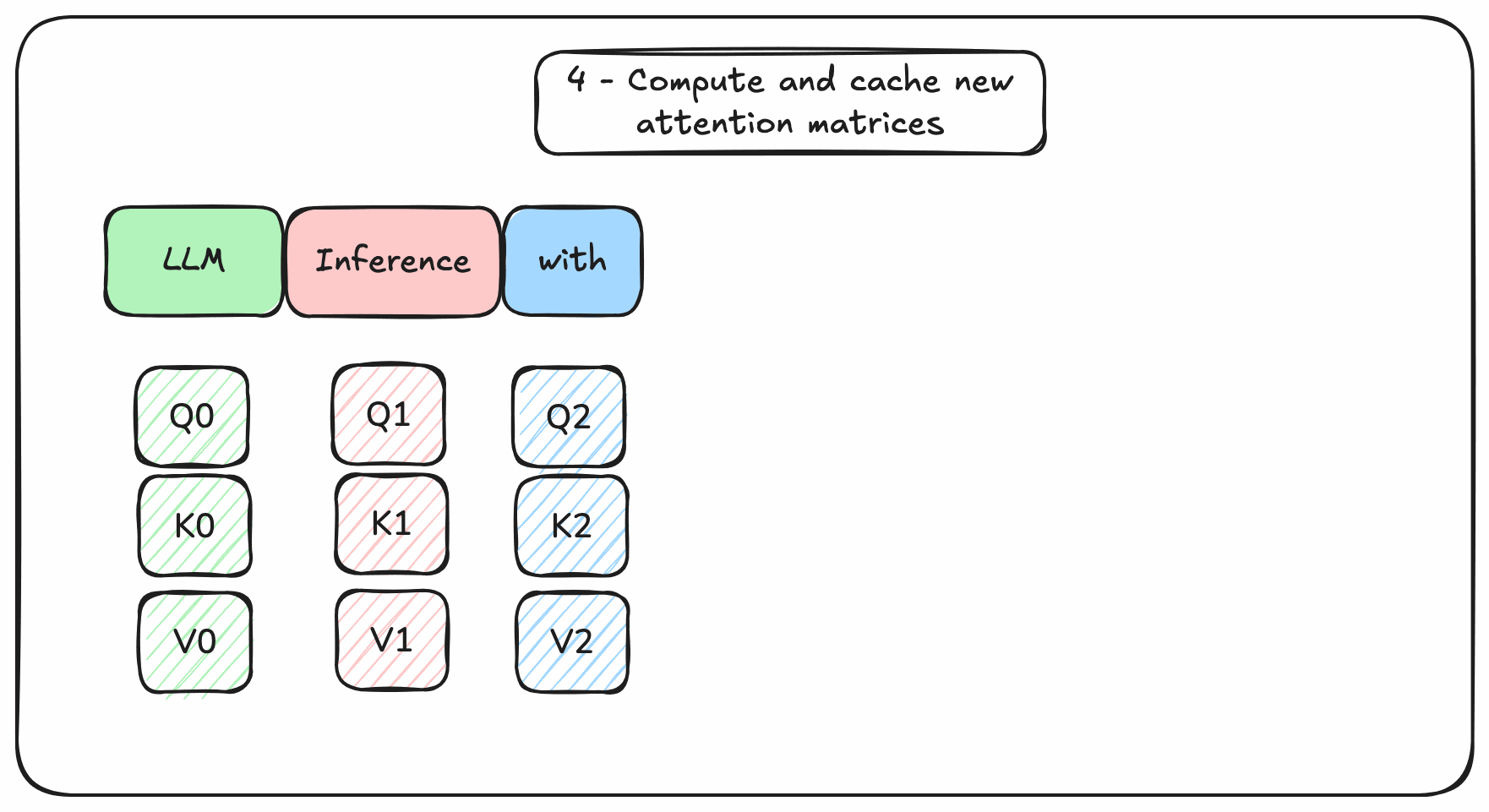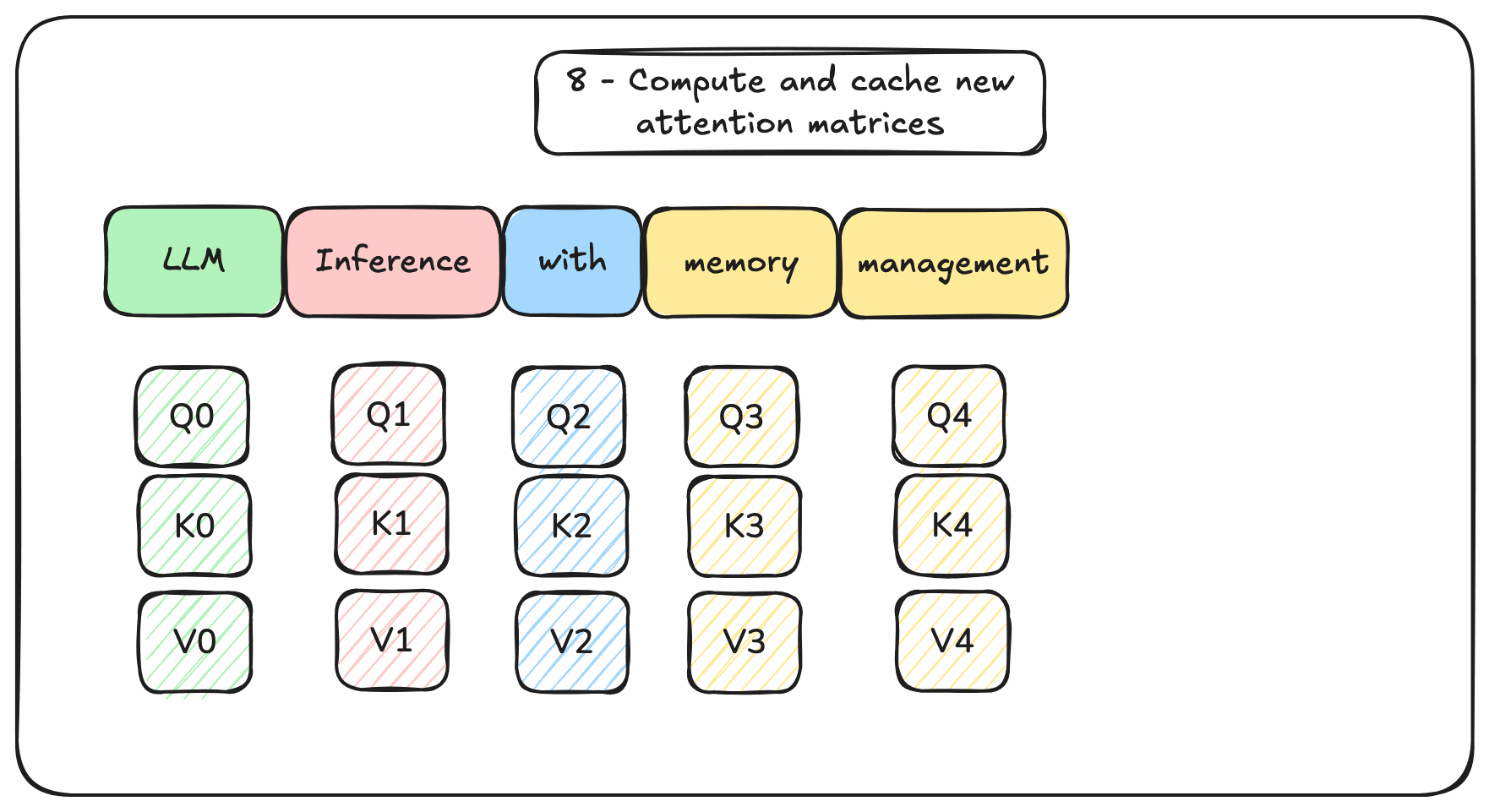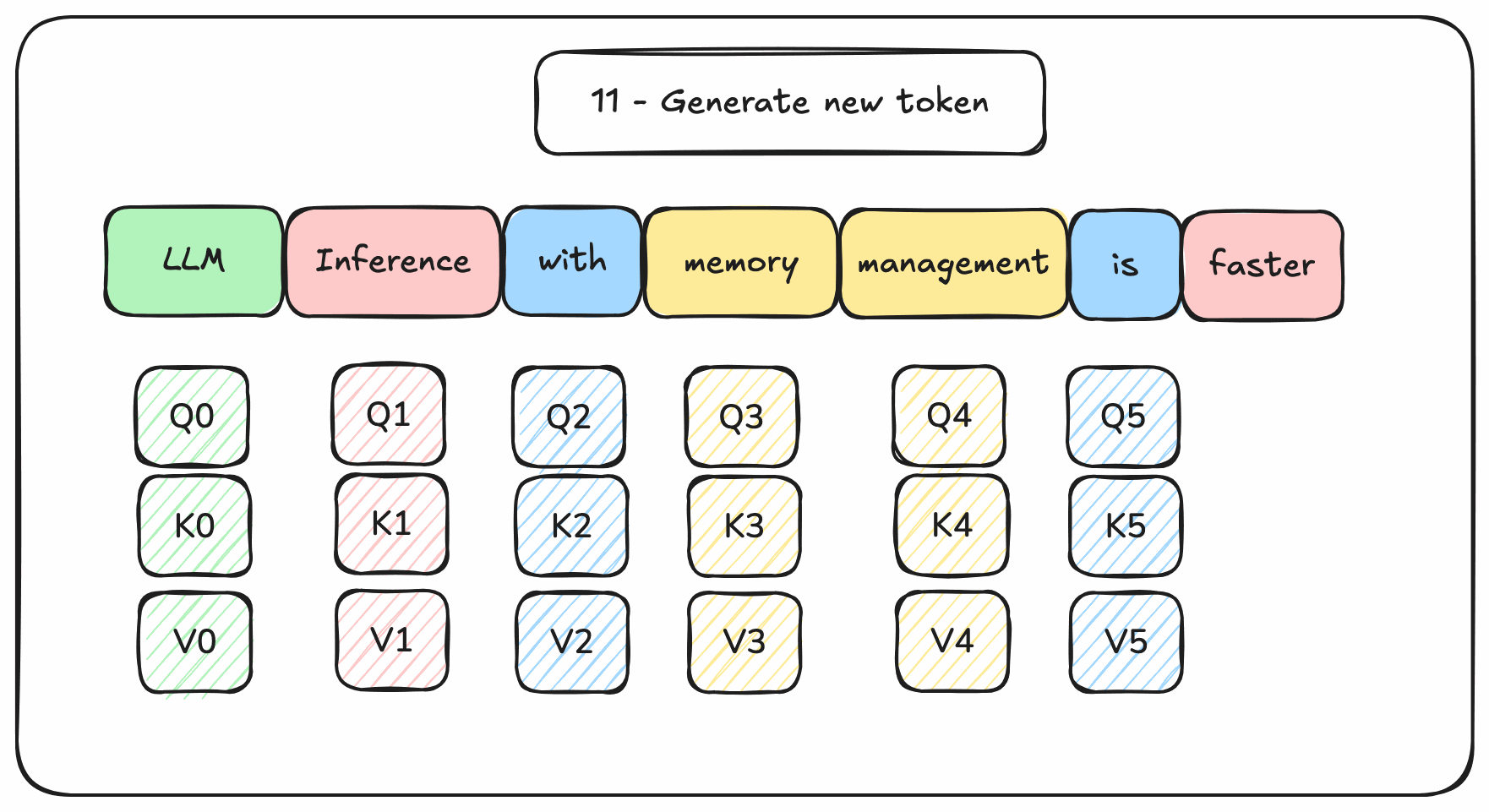 Figure 3. Transformers-based decoding with memory management
Figure 3. Transformers-based decoding with memory management
This is where problems start…
See, the computation part of generating one new token is not very intensive for a GPU, these are really good at computing dot-products (that is why Nvidia’s stock soared). So, LLM inference is not computation-bound.
However, it requires caching a lot of rows. The required storage space grows with the sequence length. At some point, the GPU may run out of memory. Hence, LLM inference is memory-bound.
Engine optimizations
The memory required to cache rows during inference is called the KV cache. Managing the size of this KV cache is the key issue of Transformers-based language models generation.
It needs to be managed: allocated, read, written, freed. This memory management is one reason why we need a LLM inference engine on top of a tensor processing framework (like PyTorch).
Also, in real use cases several sequences are usually sent in parallel to a LLM for inference (ex: one for each user). Processing these sequentially would yield a poor throughput and does not scale efficiently.
Hence, an efficient LLM inference should implement several optimizations:
- KV cache management: allocate memory depending on sequences lengths, free memory when a sequence is finished, read and write rows in between.
- Sequence batching: incoming sequences should be put together in batches to be processed in parallel, to maximize GPU utilization and minimize latency.
- Distributed execution: partition model weights across GPUs for large models, perform tensor computations in parallel on each GPU, gather the results.
- LLM specific CUDA kernels: CUDA is a C/C++ framework developed by Nvidia for GPU programming. GPU functions in CUDA are called kernels. Engines implement kernels optimized for LLM inference.
For example, vLLM implements PagedAttention, an algorithm to compute dot-products efficiently with near-optimal memory management, and continuous batching, a method to process sequences in parallel with no memory wastes and high throughput.
Want to dive into the details? You can read this article What happens behind vllm serve
vLLM provides a LLMEngine with all these optimizations. This is the backend that Triton supports.
This engine can be instantiated and used directly in a Python application.
Now, serving multiple users would require deploying this application, for example in a docker image. You would need to spawn more containers to serve more users. In this case, there would be one instance of LLMEngine in each container. Each instance would load the entire models’ weights. This would quickly strain GPU resources and thus scale poorly.
LLM inference engines implement efficient batching methods as we described. So an engine instance can be shared across several applications. It may also be beneficial to decouple the logic of the application (how the LLM is used) and the engine (how the LLM is run) instead of building a monolithic application.
This is why in practice, engines are often deployed within a standalone server process, a LLM Inference Server.
LLM Inference Servers
Although I have added “LLM” to this section, it is more for coherence than anything. The servers used to deploy the engines are not necessarily specific to language models.
vLLM and TGI include their own inference servers. These are shipped with the engines. This entanglement was the source of my confusion.
vLLM uses a FastAPI server while TGI uses Axum (Rust webserver framework).
vLLM FastAPI server is surprisingly simple. It is a REST API which supports token streaming. TGI is a bit more complex, it has native async runtime and gRPC support, thanks to Rust, making it much more production-grade.
vLLM’s performance comes mostly from its engine but its server may not be fit for production because of Python-related limitations. Hence, why Triton may actually be a good alternative to deploy the engine.
Triton Inference Server has nothing to do with LLM. It is a general purpose inference server developed by Nvidia to serve models from any backend.
It is implemented in C++, making it more efficient than vLLM’s FastAPI server. Triton comes with gRPC support like TGI but goes further. It enables to serve multiple models simultaneously, to chain models, and comes with fine-grained scheduling. It really is a production-grade general server.
However, my experience with Triton has been quite painful compared to TGI and vLLM. FastAPI might not be the most efficient but it makes prototyping with vLLM a breeze. On the other hand, Triton requires a lot more work to set up.
LLMs in Triton are best served with TensorRT-LLM, Nvidia’s own engine. I described my experience in setting up a Triton server with TensorRT-LLM backend in my previous article. Although it might be the best server for enterprise-level production, I am sticking with vLLM FastAPI server for now.
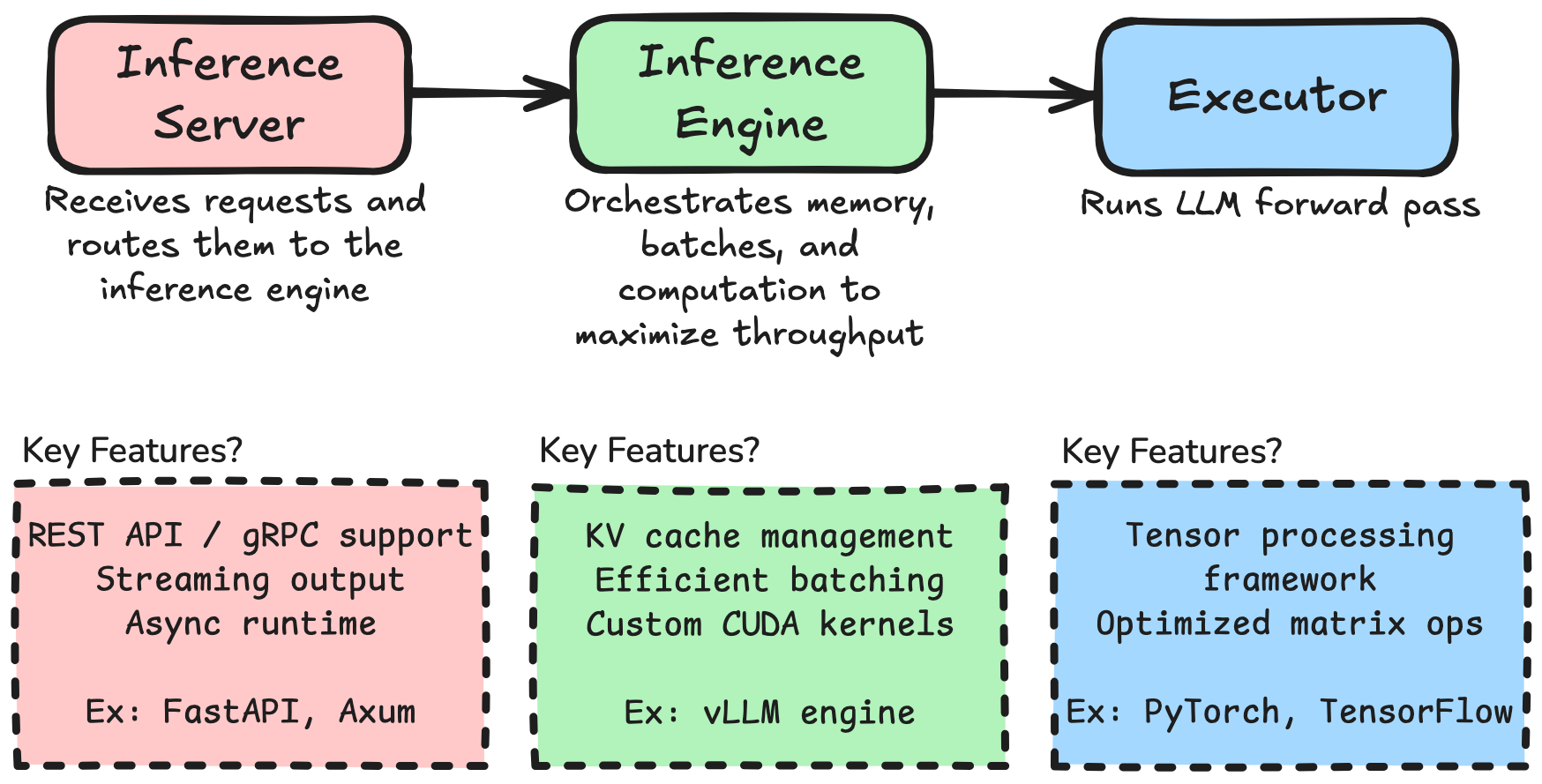 Figure 4. Overview of LLM serving framework
Figure 4. Overview of LLM serving framework
Conclusion
From a naïve question sparked by Triton’s documentation, I discovered key concepts that I did not suspect. I am glad I looked under the hood. Hopefully, this might help you too.
I try to keep things simple in these peeks, but there is much more to say about LLM inference engines and servers. If you want to dive into their optimizations, I invite you to read this article What happens behind vllm serve